
一般来说我们打开一个网站有以下几种途径:
1、直接在浏览器地址栏中输入网站网址。
2、先用搜索引擎搜索,然后找到网站进入。
3、在其他网站点击链接进入。
不管你从以上哪三种途径访问一个网站,总的来说就是一个网站接收访问者的请求和网站答复访问者的请求过程,这里面具体来说非常复杂,有各种协议在里面,但本编文章不讨论那么深奥的东西,大致讲讲访问一个网站发生了什么事。
当我们打开了一个网站(上面三种方式任意一种),其实我们并不是直接去网站的服务器(存放网站资源的地方,如文字、图片、音频等),而是先去解析网址,找到网站对应的IP地址,然后才可以找到网站的服务器。
如果在浏览器上,找网站的ip是个有趣的过程,浏览器先在hosts文件找找看有没有网址对应的IP,如果有就用这个IP,然后找到对应的服务器;如果本地电脑上没有网址对应的IP,他就会到解析网址的外部服务器中去找IP,然后找到对应的服务器;如果以上两种方式都没找到,说明网站不存在,返回错误页面。
如果弄清楚了上面访问的过程,我们就可以随意的在本地电脑上改网址所对应的IP了,只要你设置你电脑的hosts文件,可以达到这样一个好玩的现象:
你访问百度会出现搜狐网站,你访问京东会出现淘宝。
这种现象只要改hosts文件是完全可以实现的,具体为什么上面已经解释很清楚了,当你在hosts文件里把百度网址对应的IP改成搜狐IP时,当我们访问百度,浏览器会首先到hosts文件解析百度网址,把百度网址解析成的IP为搜狐IP,然后就会去搜狐服务器找资源返回给用户。
hosts文件隐藏的还是比较深的,在Windows中的全路径是:
c:\windows\system32\drivers\etc
比如上面说的百度到搜狐,京东到淘宝(IP地址网上有),设置如下:
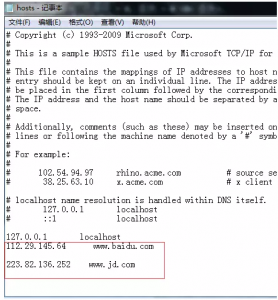
对了,这也一个访问国外网站好的方法。
高中物理知识点总结
发表回复
要发表评论,您必须先登录。